Automatic skull-face overlap
The POSEST-SFO automatic skull-face overlap algorithm estimates the camera parameters, from the coordinates of a set of pairs of cephalometric-craniometric landmarks and the corresponding soft tissue study (see Section POSEST-SFO automatic skull-face overlap).
Posest-SFO: automatic skull-face overlap
Skeleton·ID has the ability of creating a skull-face overlay (SFO) automatically, provided four or more corresponding landmarks have been located on both the photograph and the skull. This article provides an overview of the technology behind this feature.
The article Understanding camera parameters provides a gentle introduction to cameras and their role in SFO. In brief, performing a SFO means figuring out position, orientation and lens parameters of the camera taking the AM photograph. This is closely related to a classic problem in computer engineering called camera calibration. Provided with a photo of a known object (or scene), the aim is to find the position and orientation of the camera that took the photo. In Figure 1, a camera is acquiring a photo of a church from a specific position, resulting in the photograph shown in the middle of the image.
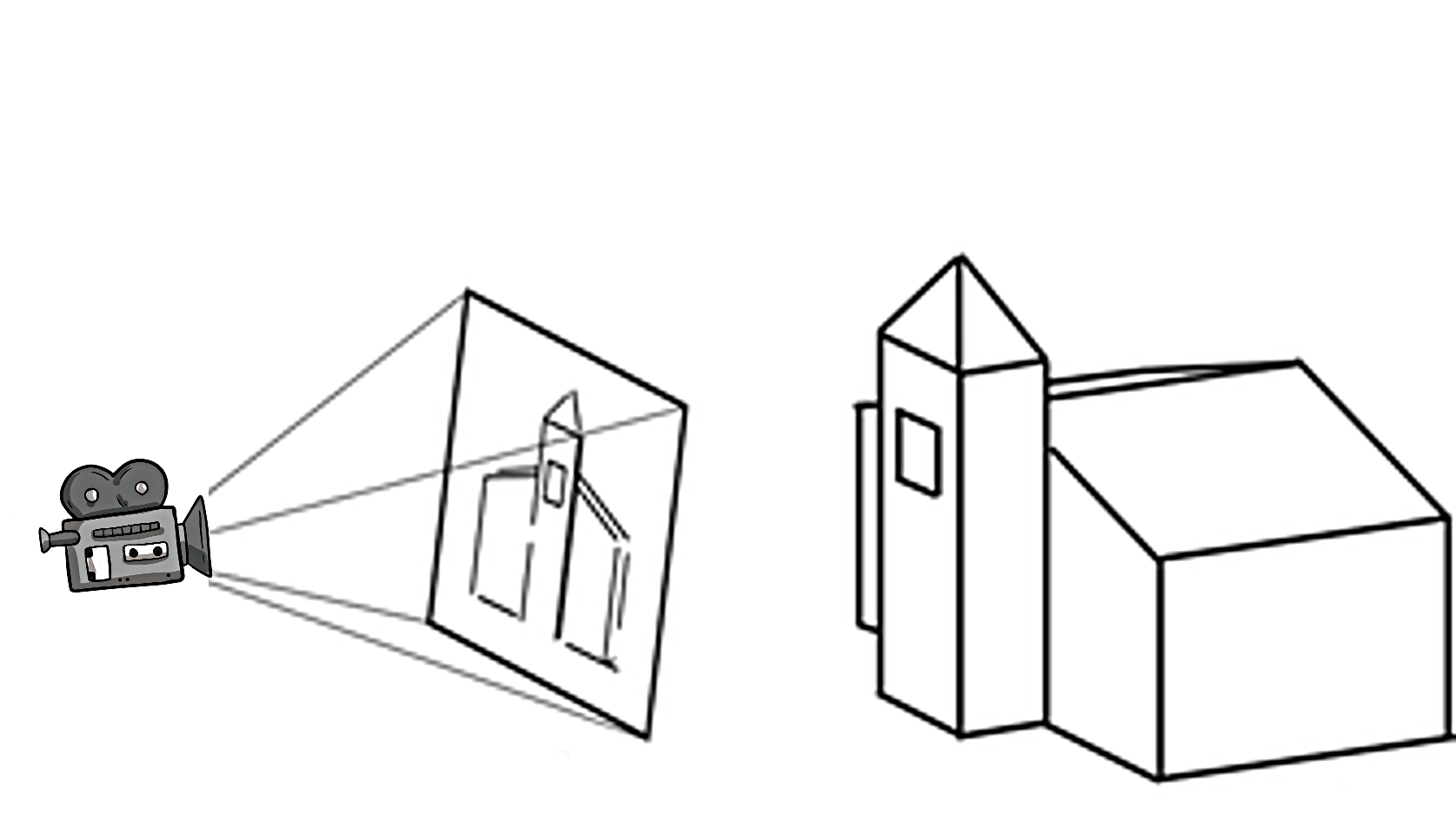 Figure 1. A camera acquiring a photo of a church from a specific position.
Figure 1. A camera acquiring a photo of a church from a specific position.
In the simplest of the camera calibration scenarios, we know exactly the geometry of the object being photographed and the lens of the camera. Also, we employ an analyst to mark a number of salient points over the photograph, such as the corners of the object (see Figure 2).
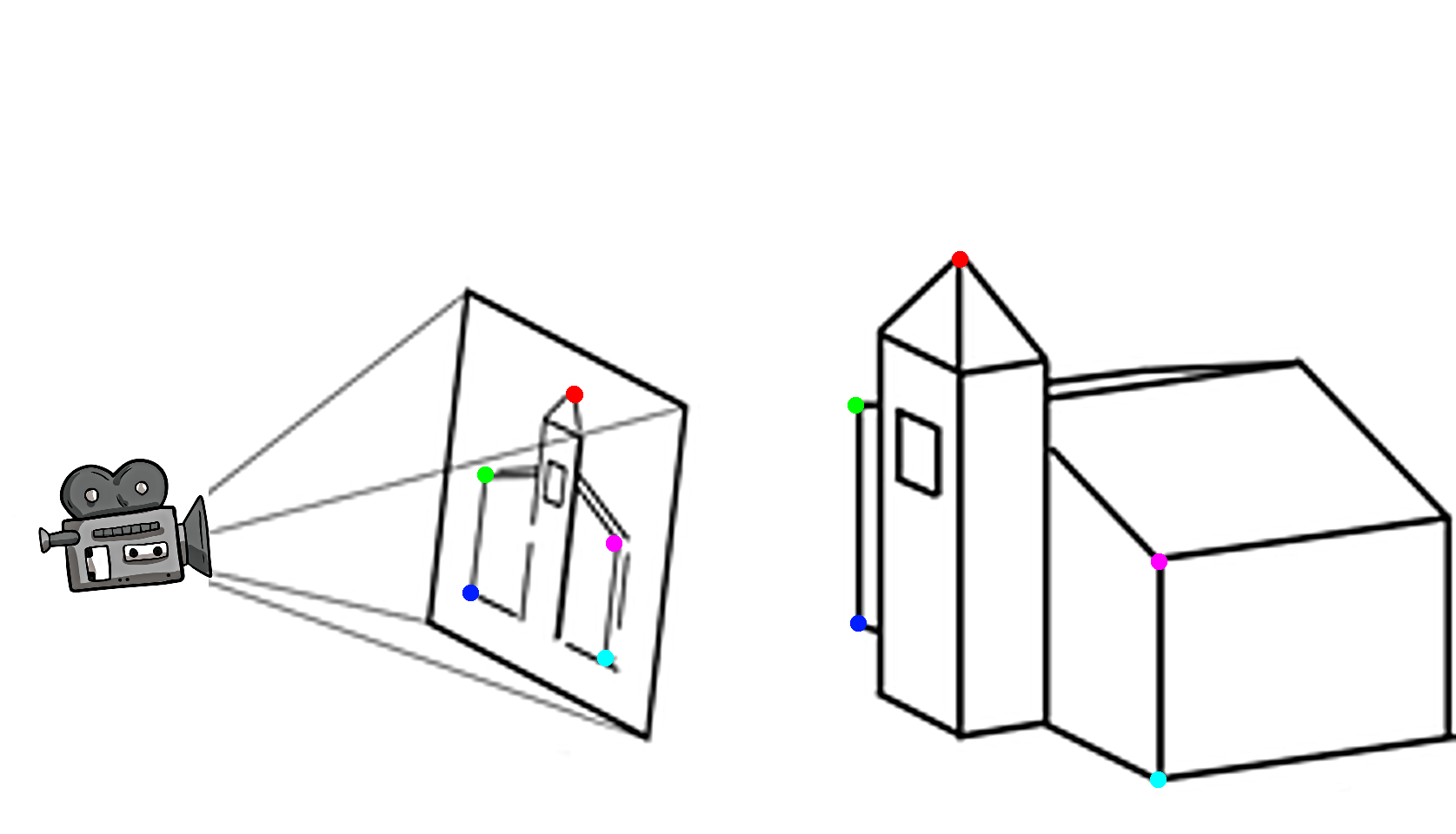 Figure 2. Corresponding reference points between the church and its photo are highlighted.
Figure 2. Corresponding reference points between the church and its photo are highlighted.
Using these landmarks, one can write a number of equations relating the position and orientation of the camera with the position of the landmarks in the photo and in the object. Solving such a system of equations using a computer yields the exact location and orientation of the camera. This problem, known as Perspective-n-Point, has been studied extensively due to its relevance in computer vision and robotics.
In the SFO problem, the role of the known object is played by the skull, and the salient points are anatomical landmarks. There are, though, two key differences with respect to the simple camera calibration scenario tackled earlier.
First, the camera lens is often unknown, especially if the photo is not from a modern digital camera. Fortunately, a recent advance in computer vision delivered a method to solve camera calibration even with unknown focal length (Bujnak et al. 2008) using as little as four landmarks.
The second difference is that, unlike in the camera calibration example, we are dealing with two objects: the skull and the face. We have to compensate for the fact that we do not know exactly the geometry of the object shown in the photo (i.e. the face), but we do know the shape of a related object (the skull). Specifically, the positions of skull and face landmarks are slightly different, due to the facial soft-tissue between the skull and face surface. Thus, we need to estimate the position of the facial landmarks based on the skull landmark, which is the same as figuring out the soft-tissue vector between the two landmarks. Each vector has two components: direction and length. The length of such vectors has been analyzed through populational studies, taking into account gender and ethnicity. As for the direction of the vector, in Skeleton·ID it is simply the perpendicular to the surface of the skull in a small region around the craniometric landmarks (Figure 3). Additionally, it can also be determined by the user as part of the landmarking process.
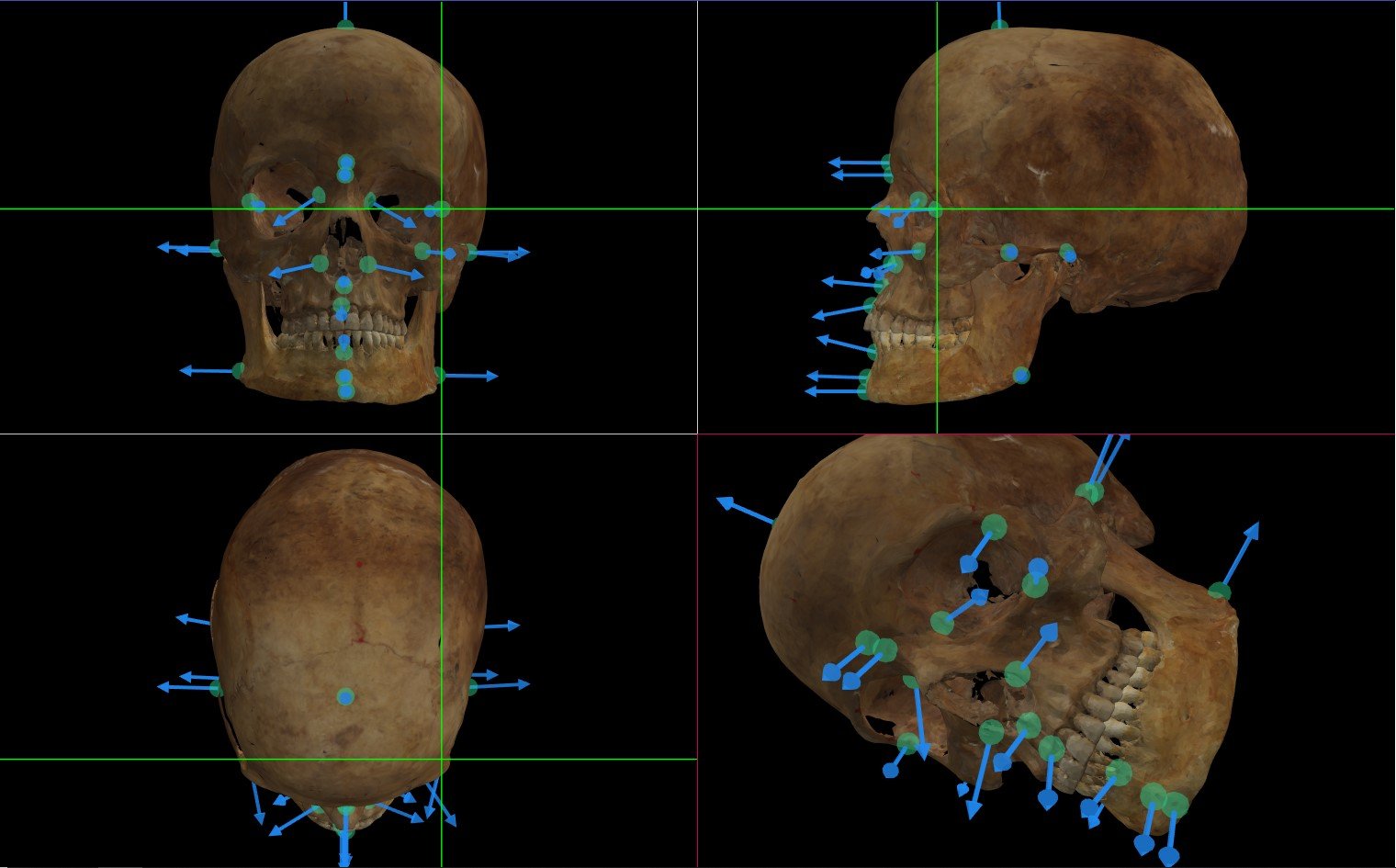 Figure 3. A screenshot of Skeleton·ID showing a 3D skull with craniometric landmarks (green points) and soft-tissue vectors (blue arrows) pointing towards the corresponding facial landmarks.
Figure 3. A screenshot of Skeleton·ID showing a 3D skull with craniometric landmarks (green points) and soft-tissue vectors (blue arrows) pointing towards the corresponding facial landmarks.
Following these principles, we have developed a novel algorithm to automatically perform SFO called Posest-SFO (Valsecchi et al. 2018). To run the algorithm, the following data is required as input:
-
A list of at least four pairs of facial and skull landmarks.
-
A soft tissue study including at least the mean soft tissue depth distance for the selected pairs of landmarks.
-
Soft tissue direction for each craniometric landmark (vectors).
As a result, Posest-SFO estimates the set of camera parameters that minimizes the distance between cephalometric landmarks and their corresponding craniometric once applying the vector’s direction and the mean soft tissue information. Figure 4 depicts the resulting SFO once applying Valsecchi’s algorithm. Posest-SFO computed position, orientation and focal length of the camera.
 Figure 4. A SFO computed by Posest-SFO. On the left side we the estimated camera parameters are depicted: focal (31.31 mm) and subject-to-camera distance (912.72 cm) among others. Pink dots represent cephalometric landmarks and green-yellow “tubes” the corresponding soft tissue thickness and direction. The green region represents the most common values, while the yellow region represents the realistic values..
Figure 4. A SFO computed by Posest-SFO. On the left side we the estimated camera parameters are depicted: focal (31.31 mm) and subject-to-camera distance (912.72 cm) among others. Pink dots represent cephalometric landmarks and green-yellow “tubes” the corresponding soft tissue thickness and direction. The green region represents the most common values, while the yellow region represents the realistic values..
-
Speed: Valsecchi’s method is extremely fast, as it provides the resulting SFO in 80 milliseconds. This allows the automatic superimposition of one skull over a database of hundreds of missing persons in a matter of seconds.
-
Accuracy: this algorithm has been properly studied (see Valsecchi et al., 2018 for detailed statistical data). In particular, it showed a mean error of 2 mm in a dataset of 540 SFOs using 9 pairs of landmarks. This error increases as the number of landmark pairs decreases, in particular, 2.2, 2.5, 3.0 and 3.8 mm error for 8, 7, 6 and 5 landmark pairs, respectively.
Final remarks and work in progress
Skeleton·ID’s automatic SFO algorithm is fast and accurate. However, its accuracy is directly related with the quantity and quality of the data. In particular, a large number of landmark pairs (>8) precisely located together with adequate soft tissue depth and direction information is crucial to increase the accuracy and confidence in the automatic results.
Despite the outstanding results provided by Posest-SFO, we are working to improve it by:
-
Modelling mandible articulation within the SFO automatic process.
-
Estimating ad-hoc soft tissue depth and direction information.
-
IIncorporating a priori information (raw pose, estimated subject-to-camera-distance and / or focal distance).
References
M. Bujnak, Z. Kukelova, and T. Pajdla, “A general solution to the P4P problem for camera with unknown focal length,” in 2008 IEEE Conference on Computer Vision and Pattern Recognition, 2008.
Valsecchi, A., Damas, S., Cordón, O., 2018. A Robust and Efficient Method for Skull-Face Overlay in Computerized Craniofacial Superimposition. IEEE Transactions on Information Forensics and Security 13 (8), 1960-1974.
Launch POSEST-SFO algorithm on Skeleton·ID
-
To launch the algorithm, we will click on the button
 located under the screenshots tab.
located under the screenshots tab. -
The algorithm configuration window will appear (Figure 5), from where we can select which pairs of landmarks will guide the algorithm (by default all possible pairs will be used).
 Figure 5. POSEST-SFO algorithm configuration.
Figure 5. POSEST-SFO algorithm configuration.
- Pressing the run button Will close the sale and in a matter of a second the resulting skull-face overlap will be displayed. If any of the included pairs does not contain tissue thickness data in the study used, an error will appear indicating that no data has been found for that pair (Figure 6) and the algorithm will not start. In this case, we must deselect those landmarks that are indicated to us and press the run button again.
 Figure 6. The algorithm indicates that in the soft tissue study used there are no data for the Exocanthion-Ectoconchion pair, so we must deselect this pair in the list of homologous landmarks.
Figure 6. The algorithm indicates that in the soft tissue study used there are no data for the Exocanthion-Ectoconchion pair, so we must deselect this pair in the list of homologous landmarks.
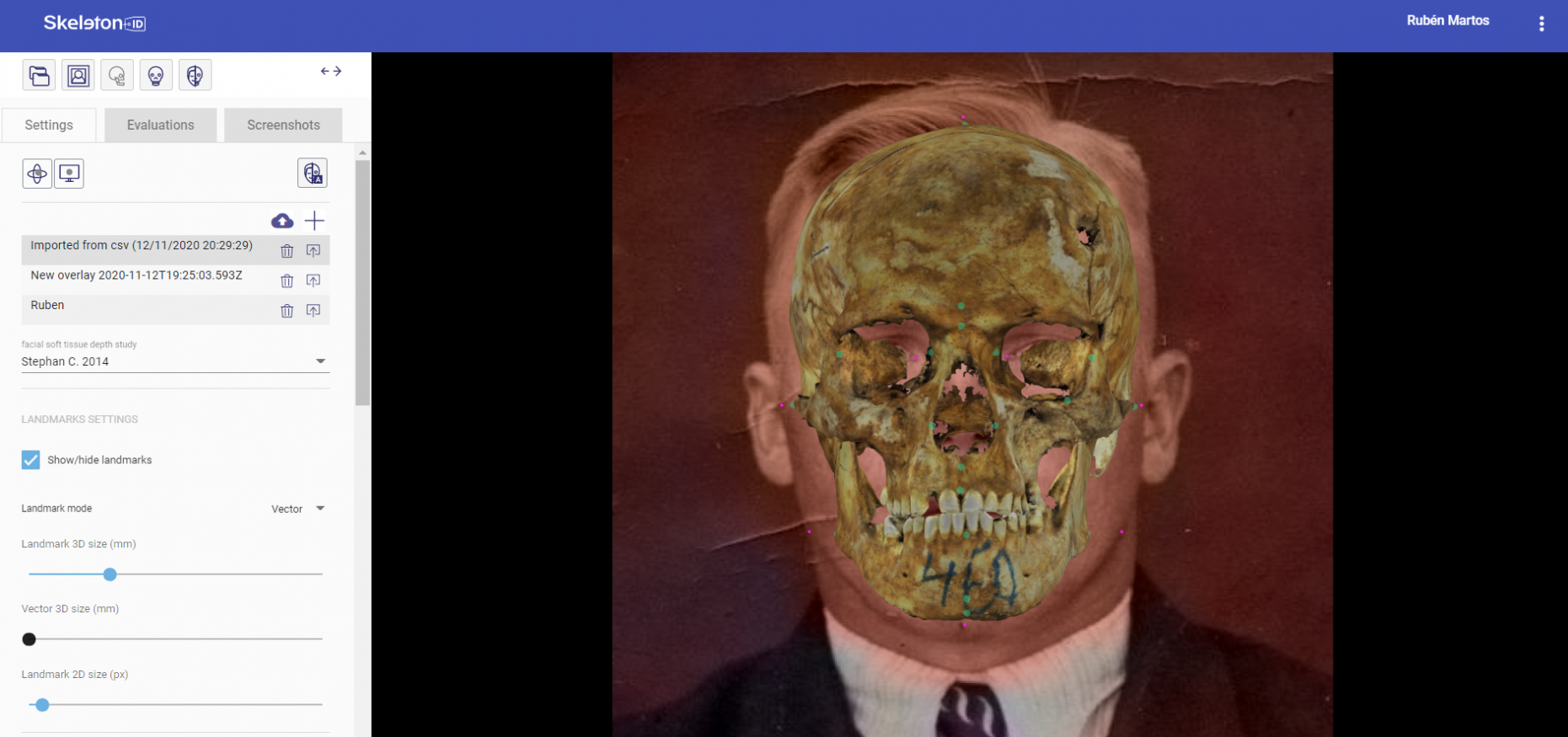 Figure 7. Skull-face overlap obtained using the POSEST-SFO algorithm.
Figure 7. Skull-face overlap obtained using the POSEST-SFO algorithm.